I've recently had the opportunity to get a bit more familiar with Azure Data Factory V2. In Microsoft's words "it is the cloud-based ETL and data integration service that allows you to create data-driven workflows for orchestrating data movement and transforming data at scale. Using Azure Data Factory, you can create and schedule data-driven workflows (called pipelines) that can ingest data from disparate data stores. You can build complex ETL processes that transform data visually with data flows or by using compute services such as Azure HDInsight Hadoop, Azure Databricks, and Azure SQL Database."
While the product is very powerful and yet fairly simple to use (being a no-code solution), it differs quite a bit from other Azure products from the CI/CD & DevOps perspective and often requires some additional thought to go into ARM template creation and repository structures.
At a high level, the development version of the data factory is attached to a repository. Development itself is often done in the Data Factory portal, from where the code representation of the configuration is saved into the repository using normal branching strategies. After we are ready take something into production, we publish the current version of the "collaboration branch" (often master), which prompts Data Factory to autogenerate ARM templates in a "publish branch" that can be used to configure the environments further along the way.
Sounds simple, right?
"Best practice"
Microsoft suggests the following structure for the flow:
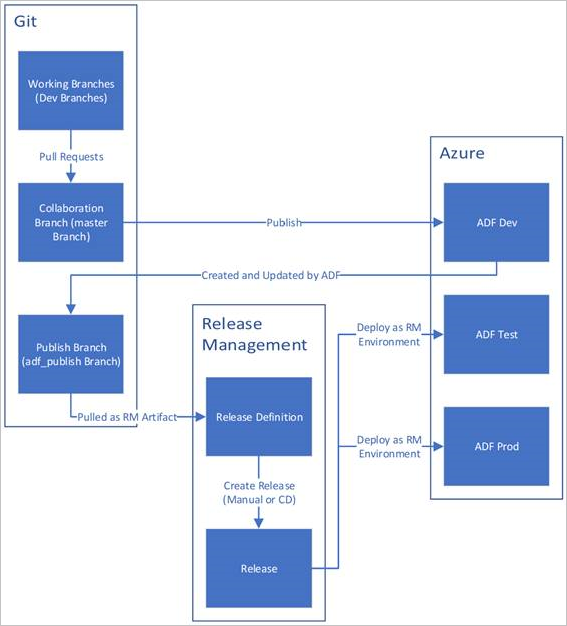
This should be all good, but at least in our situation introduced some difficulties:
- Our repository holds other content alongside the ADF code, but the publish branch of course does not include anything other than the ARM templates. Our chosen branching strategy & naming requires everything included.
- The autogenerated ARM templates only contain the contents of the Data Factory, not the resource itself
- Complete mode ARM deployments require all ARM stuff to be deployed together, as they delete everything not included
Our solution
Repository structure
The project currently deploys to production roughly every two weeks, as we are using Microsoft's Release Flow. We ended up keeping the solution in the same repository, and merging the publish branch to master when changes are made. Once it is time to create a release branch, everything is neatly in the same place.
Arm Templates
We are using linked templates, so both the base template with the ADF resource as well as the autogenerated templates need to be included to not be wiped away by Complete mode.
The base template needs to add our Azure Repos git repository to the development ADF, but not to others. The repo configuration however, is not a subresource, but instead just a part of the "properties" object of the ADF itself. Thus the configuration is done in a variable and an if condition is added to that object instead of the whole resource. This also works around the need to somehow include two resources with the same name in the template.
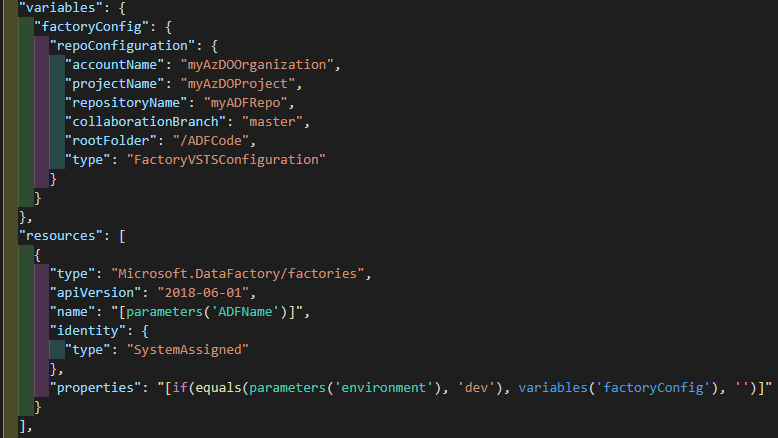
The main template in the linked template structure then needs to have a condition to not deploy the autogenerated template for the Dev environment as it might not exist. This is easily done with a condition. The required parameter names can be checked from the autogenerated version.
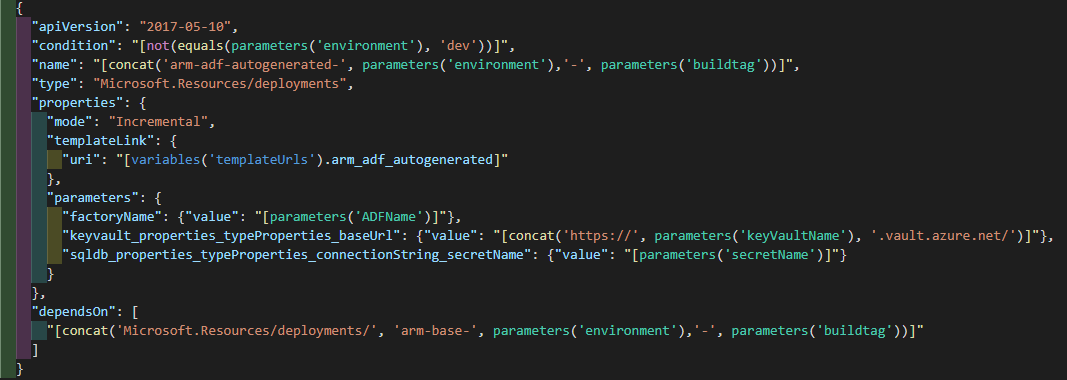
The autogenerated files can also be created manually from the ADF portal at any point in case you need to check the required parameters before the first deployment.

Deployment pipelines
Thankfully this part is fairly simple, as the only thing we need to do is to make sure that all the ARM templates are located in a publicly available location for the linked template deployment. For this, a storage account with a short lived SAS-token will work very well and can be automated using the Azure File Copy task and its outputStorageContainerSasToken-parameter in Azure DevOps.
steps:
- task: AzureFileCopy@2
displayName: 'ARM to SA for deployment'
inputs:
SourcePath: '$(System.DefaultWorkingDirectory)/_ARM Deployment Artifacts/Deployment'
azureSubscription: 'mySubscription'
Destination: AzureBlob
storage: armstorage
ContainerName: '$(environment)'
outputStorageUri: containerUri
outputStorageContainerSasToken: containerSAS
And lastly just deploy the ARM by using the Azure Resource Group Deployment task
Sources & Further reading
Introduction to Azure Data Factory
Source control in Azure Data Factory
Continuous integration and delivery (CI/CD) in Azure Data Factory