I’ve been refining my own mental model for agent splits in coding workflows, and this post is a snapshot of what has worked best so far.
A lot of this aligns with ideas from Dex Horthy’s talk from the AI Engineer Code Summit (YouTube) and with the way I’ve been structuring Research-Plan-Implement flows (my post here).
I also touched adjacent concepts in A mental model for LLM tooling primitives.
The short version
- Primary agents are user-facing orchestrators.
- Subagents are context protectors and scoped executors.
- If a split doesn’t reduce context pressure, it’s probably not a useful split.
That’s really it.
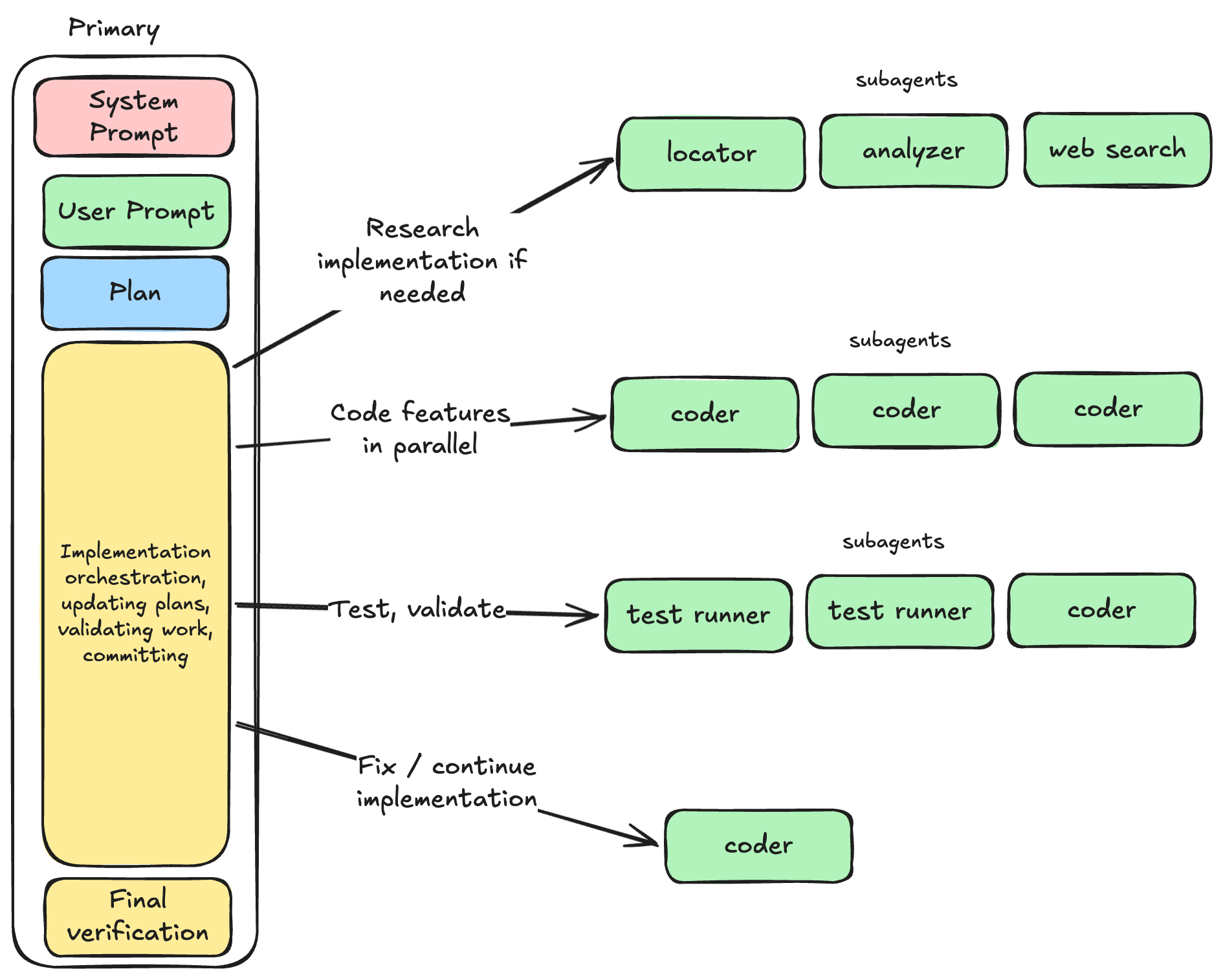
What primary agents should do
Primary agents should be the only layer directly responsible for user interaction and overall task flow.
They define:
- how the session should behave,
- what kind of output should be returned,
- when to delegate work,
- and how to synthesize results into a final answer.
In practice, primary agents should mostly orchestrate and synthesize. They can do work themselves too, but for bigger tasks their main value is coordination.
A useful framing: primary agent = director, not every actor on stage. (Though as always, there are cases where it can do everything. Depends on the size of the task you're currently working on)
What subagents should do
Subagents should exist primarily to protect the context window of the primary agent.
Not “security agent”, “SRE agent”, “backend agent” by default.
Instead: small, narrow units of work that return distilled outcomes.
Good subagent jobs:
- locate files relevant to a topic,
- analyze a specific code path,
- find existing patterns,
- implement one atomic change set,
- summarize prior research/decisions.
What they return should usually be compact and structured. This could be a short summary, file paths + line pointers, key findings / decisions or explicit gaps. So not full file dumps unless absolutely necessary.
Common failure mode I keep seeing
Sometimes the primary agent asks subagents for too much, like: “return full contents of the files”, “return all changes in detail” or “paste everything you found”
That defeats the whole point of the split and wastes money and time as well, so it's important to catch when it happens.
The solution is to fix the primary prompt so subagents return distillations instead. If the primary needs full content, it can read targeted files itself afterward.
Parallelism is not optional
If subagent tasks are independent, the primary should spawn them in parallel.
Typical good parallel batches:
- multiple locators on different search angles,
- independent implementation tasks touching disjoint files,
- separate analyzers for code, patterns, and prior notes.
This is usually the easiest way to reduce wall-clock time without losing quality. The primary agent is often smart enough to make these decisions, but the risk exists that there is some underlying dependency that can affect the coherency of the final result.
Share plan artifacts explicitly
Subagents do not magically inherit full context from the primary.
So when there is a plan/research artifact, instruct the primary agent to pass the link/path directly in the subagent prompt.
This is exactly why I like writing explicit plan files in the first place (again: Research-Plan-Implement): they become stable handoff artifacts between agent hops.
Without that handoff, primaries often assume subagents “know the whole story”, and that assumption breaks quickly. The subagents can then read the plan to get the full context (e.g. what are we doing? What has already been done so far?). If your plans aren't massive, this should be fine from the context perspective.
A practical contract I like for subagent responses
I haven't spent enough time on tuning these yet myself, but something like this could be used as a guideline when designing what the subagents return. Often the primary agent's prompt gives the instructions anyway, so it feels more powerful to tune that instead.
- Result: 3–7 bullets max
- Evidence: path:line references
- State: done / partial / blocked
- Next input needed: one short line (if blocked)
Implementation examples
Here are a few of the subagents I'm using. Mostly taken from the humanlayer repository.
- codebase-locator
Finds where things live, grouped by purpose. No deep analysis. - codebase-analyzer
Explains how specific flows work with precise file:line references. - pattern-finder
Finds established implementation/test patterns to mirror.
Final thoughts
For me, primary/subagent design is mostly a context engineering problem, not a role taxonomy problem.
If your primary agent is drowning in tokens, make subagents narrower.
If your subagents are returning novels, tighten response contracts.
If execution is slow, parallelize independent work.
If context gets lost, pass explicit plan files.
Everything else is details.